Search engines have a problem: Websites often include a wealth of data that is extremely useful but difficult to decipher.
For example, on a complex entertainment site built from a large database, how can Google quickly determine whether the page content is about a movie, a person, or a TV series?
To address this issue, a group of search companies—Google, Microsoft, Yahoo, and Yandex—agreed three years ago to use a common set of identifiers (schemas) to help flag the various "entities" on a page.
This effort to structure Web data, which is housed under the Schema.org umbrella, assigns specific HTML tags to types of things—such as events, recipes, reviews, locations, etc.—so that search engines can recognize them.
The project began in 2011 and has picked up momentum over the past year as the companies involved have increasingly stressed its importance.
Of course, the integration of these markups clearly helps search engines by providing better data. But does it help publishers? Does Schema.org integration actually improve rankings in search results?
In a recent report, Searchmetrics set out to answer that question by examining hundreds of thousands of websites for Schema.org integrations and then analyzing whether those inclusions affected the search result rankings for tens of thousands of keywords.
The first finding was that very few sites have Schema.org integrations—only 0.3% of all those examined.
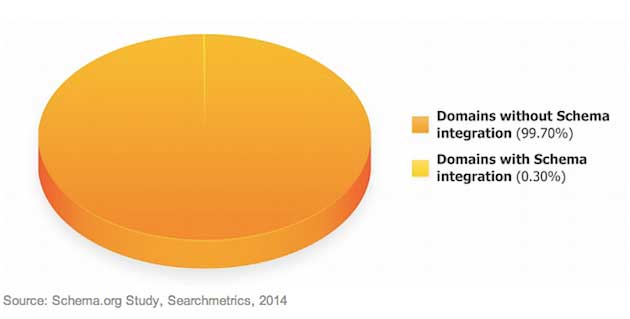
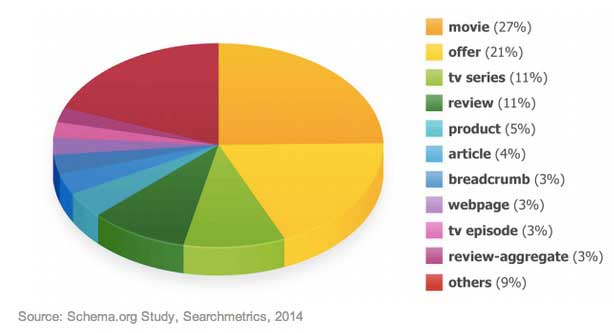
Though few sites use markups, the analysis found those that do often use multiple tags—sometimes integrating up to seven different ones.
The most common markup type is "movies" (27%), followed by "offer" (21%), "tv series" (11%), and "review" (11%).
Next, Searchmetrics examined how these markups affected search rank by looking at the top 50 search results for various keywords.
The analysis found that sites without Schema,org integration ranked 25th on average in Google results, whereas those with integration ranked 21st on average—a four-position increase.
The results show promise, according to the researchers, but they were clear to note that they could not definitively link the higher average search rank with markup use.
That said, Searchmetrics was able to see that Google is clearly relying heavily on structured data: 36% of the keyword queries examined included some information (a "rich snippet") from at least one site with Schema.org integration.
About the research: The report was based on an analysis of hundreds of thousands of websites and the the search results for tens of thousands of keywords.



